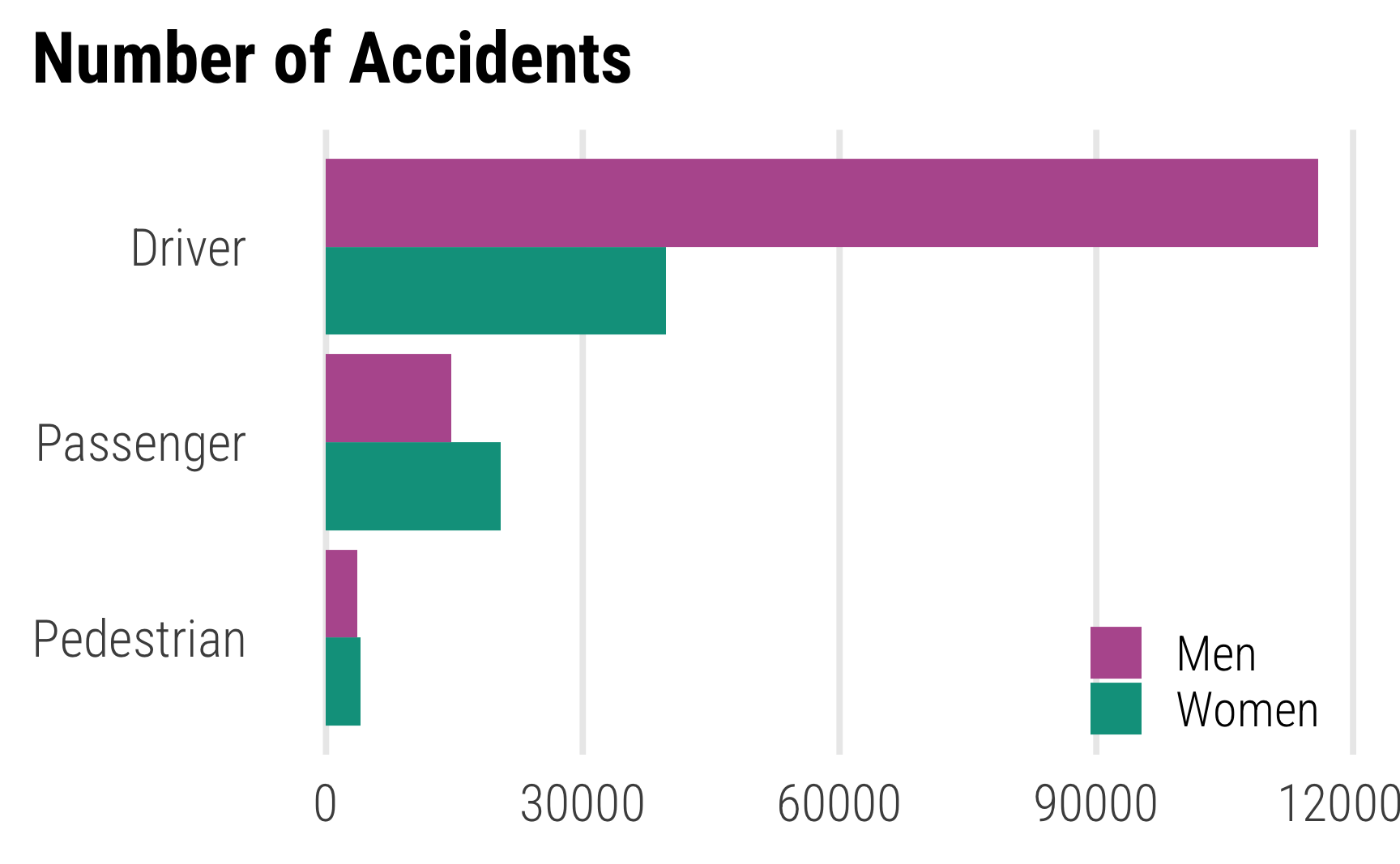
--- title: Madrid Traffic Accidents Dataset author: Kazuharu Yanagimoto date: 2024-03-24 categories: [descriptive, traffic accidents] --- [ dataset ](https://datos.madrid.es/portal/site/egob/menuitem.c05c1f754a33a9fbe4b2e4b284f1a5a0/?vgnextoid=7c2843010d9c3610VgnVCM2000001f4a900aRCRD&vgnextchannel=374512b9ace9f310VgnVCM100000171f5a0aRCRD&vgnextfmt=default) .`code/00_download/` and `code/01_cleaning/` .[ GitHub repository ](https://github.com/kazuyanagimoto/workshop-r-2022) ```{r} #| label: setup #| include: false :: opts_chunk$ set (fig.width = 6 ,fig.height = (6 * 0.618 ),out.width = "80%" ,fig.align = "center" ,fig.retina = 3 ,collapse = TRUE ``` ```{r} #| label: library-data #| include: false library (tidyverse)library (fixest)library (tinytable)library (modelsummary)library (targets)tar_config_set (store = here:: here ("_targets" ),script = here:: here ("_targets.R" )tar_load (c (accident_bike))invisible (list2env (tar_read (fns_graphics), .GlobalEnv))theme_set (theme_proj ())``` ```{r} #| label: figure-num-accidents |> ggplot (aes (x = fct_rev (type_person), fill = fct_rev (gender))) + geom_bar (position = "dodge" ) + coord_flip () + scale_fill_gender () + labs (x = NULL , y = NULL , fill = NULL , title = "Number of Accidents" ) + theme (legend.position = c (0.85 , 0.1 ), panel.grid.major.y = element_blank ()) + guides (fill = guide_legend (reverse = TRUE ))``` ## Logit Regression of Hospitalization and Death ```{r} #| label: table-logit-hospital-death <- list ("(1)" = feglm (~ + positive_alcohol + positive_drug | age_c + gender,family = binomial (logit),data = accident_bike"(2)" = feglm (~ + + | + gender + type_vehicle,family = binomial (logit),data = accident_bike"(3)" = feglm (~ + + | + gender + type_vehicle + weather,family = binomial (logit),data = accident_bike"(4)" = feglm (~ type_person + positive_alcohol + positive_drug | age_c + gender,family = binomial (logit),data = accident_bike"(5)" = feglm (~ + + | + gender + type_vehicle,family = binomial (logit),data = accident_bike"(6)" = feglm (~ + + | + gender + type_vehicle + weather,family = binomial (logit),data = accident_bike<- c ("type_personPassenger" = "Passenger" ,"type_personPedestrian" = "Pedestrian" ,"positive_alcoholTRUE" = "Positive Alcohol" <- tibble (raw = c ("nobs" , "FE: age_c" , "FE: gender" , "FE: type_vehicle" , "FE: weather" ),clean = c ("Observations" ,"FE: Age Group" ,"FE: Gender" ,"FE: Type of Vehicle" ,"FE: Weather" fmt = c (0 , 0 , 0 , 0 , 0 )modelsummary (stars = c ("+" = .1 , "*" = .05 , "**" = .01 ),coef_map = cm,gof_map = gm|> group_tt (j = list ("Hospitalization" = 2 : 4 , "Died within 24 hours" = 5 : 7 ))```